PRODUCT TOUR
See it in action.
companybrain.app/login
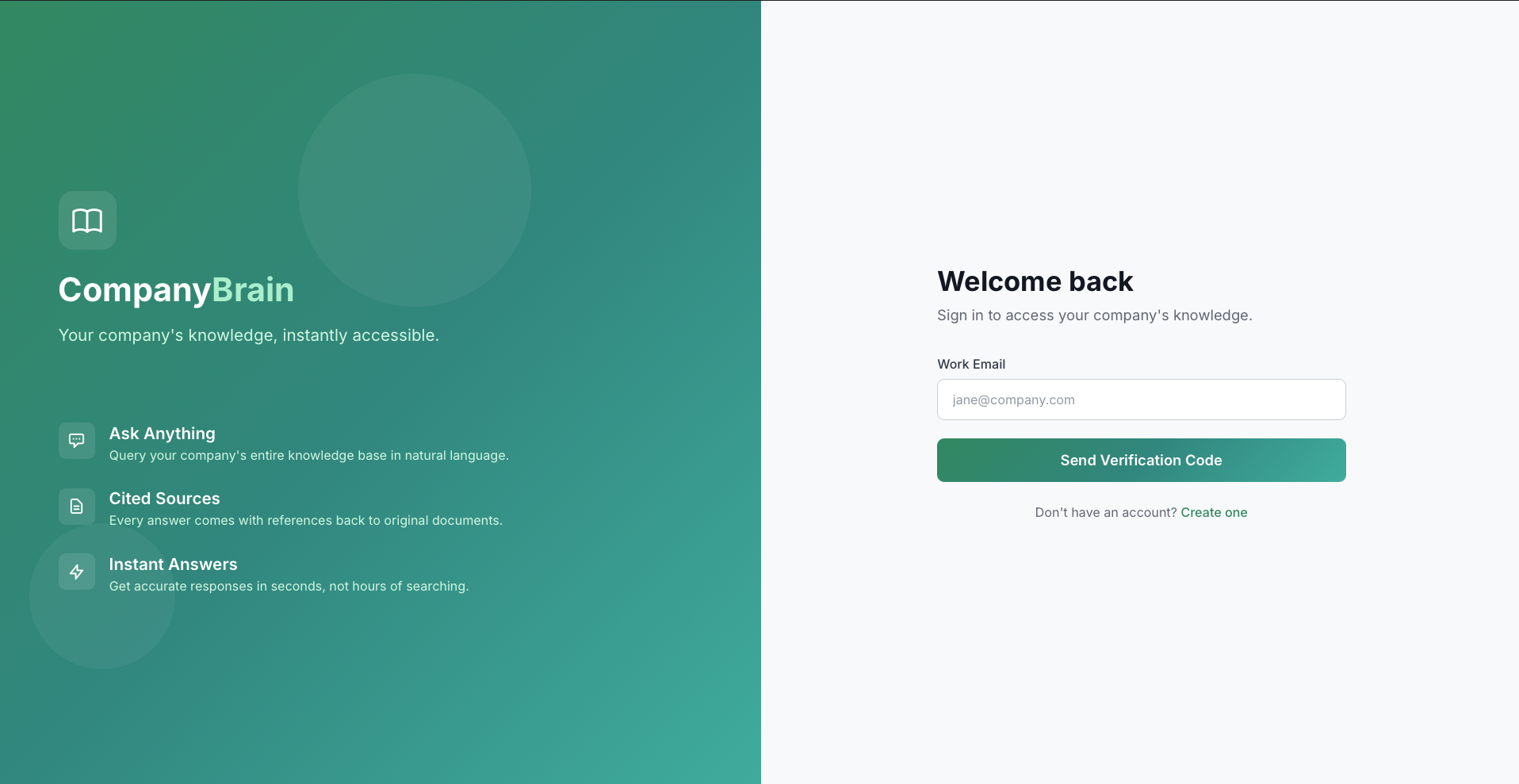
Passwordless OTP login
Email-based, 6-digit code, session token with expiry.
companybrain.app/documents
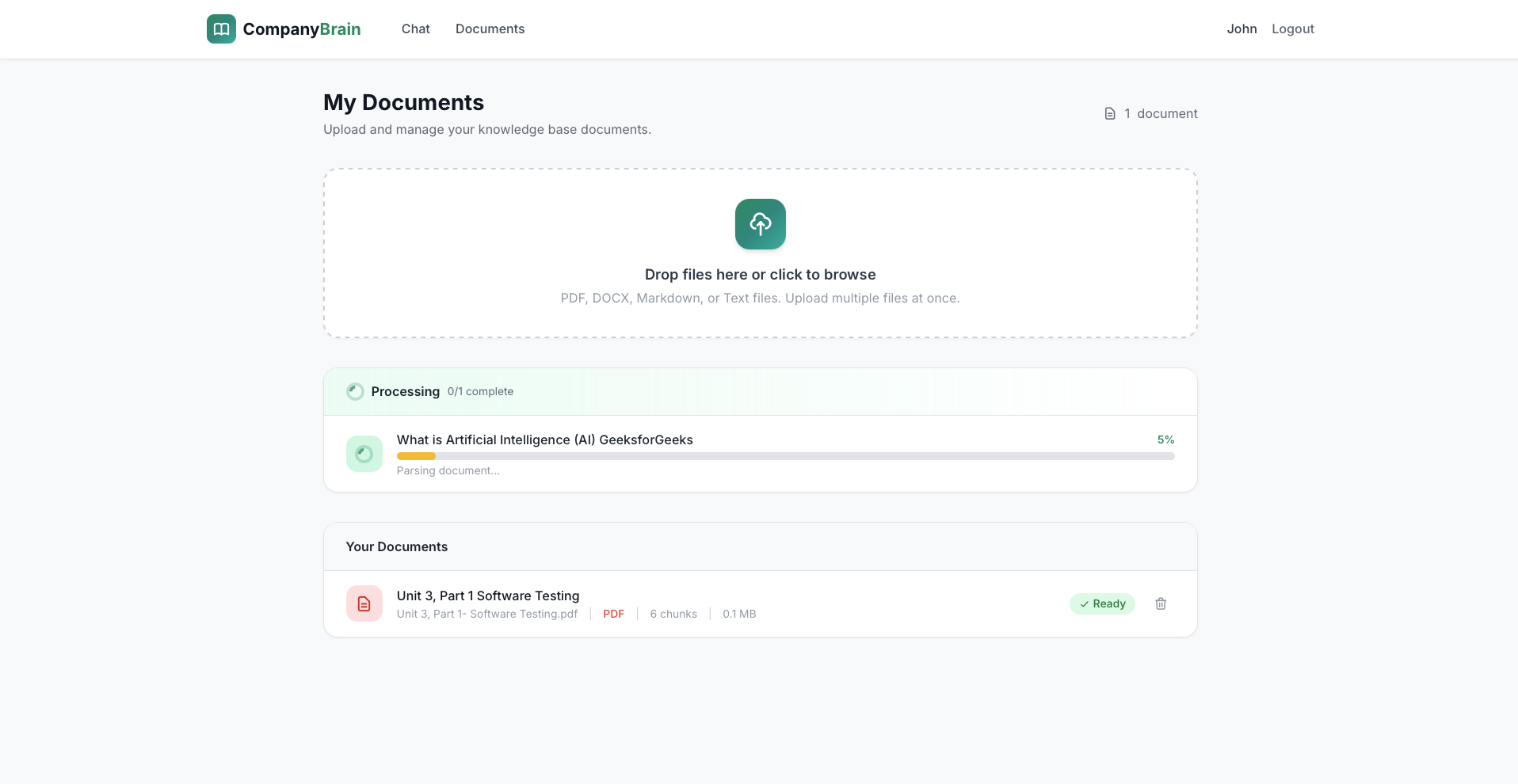
Document management
Upload, processing progress, chunk count, status, delete.
companybrain.app/chat
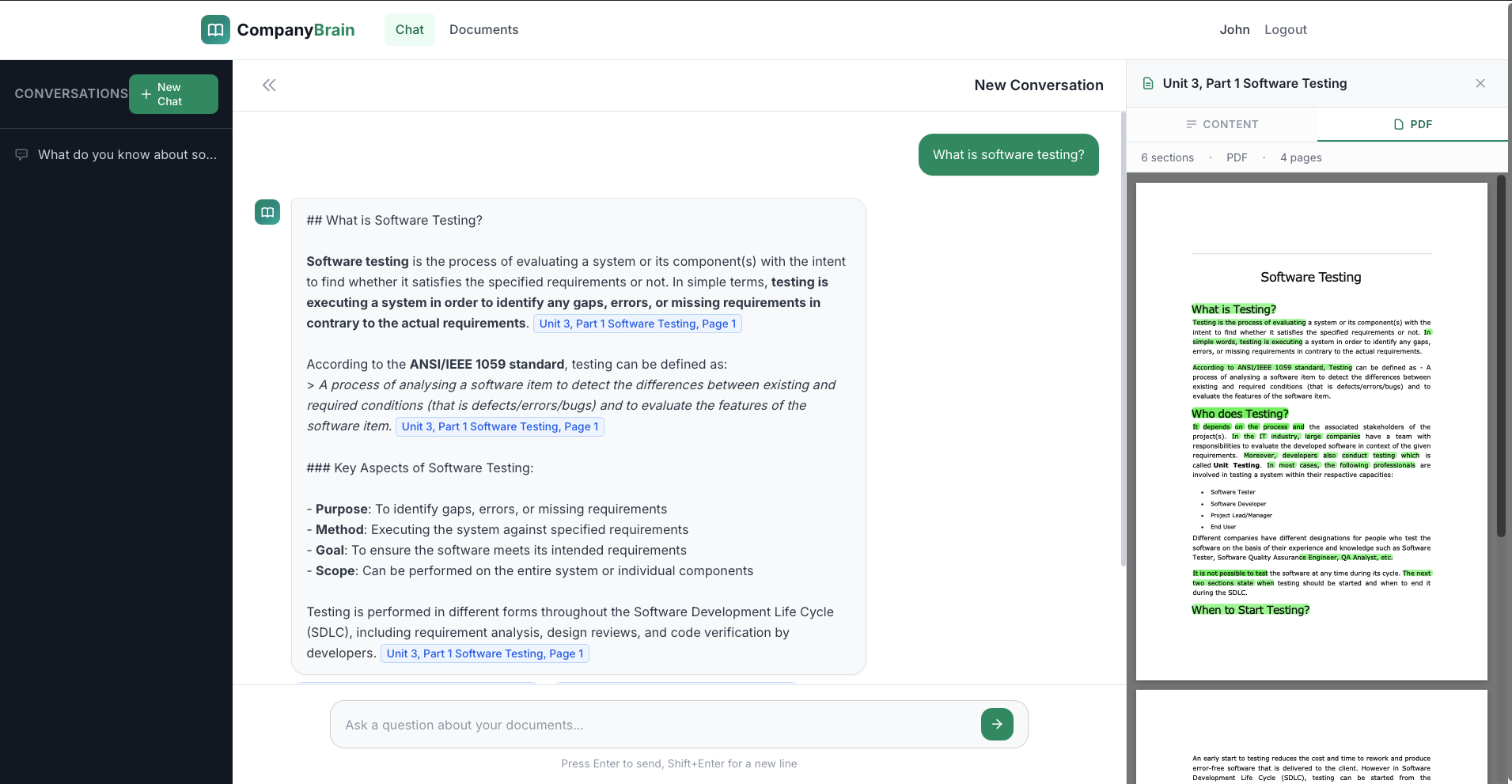
RAG chat with sources
Streaming answers, cited sources, confidence scores, multi-turn memory.